A recent paper by DeepMind in Nature caused great shocks in the AI ​​field and in the neuroscience field: AI exhibits a spatial navigation capability that is highly consistent with the human brain "grid cells." Some scholars even believe that with this paper, the author of DeepMind may aspire to the Nobel Prize. The author of this article, Dr. Deng Wei, interpreted this breakthrough paper.
Google’s DeepMind Company will not only play Go, but also write top essays.
2018/5/10, Today's WeChat circle of friends was screened by DeepMind. The paper was published in a recent issue of Nature magazine. The topic is Vector-based navigation using grid-like representations in artificial agents [1].

Some scholars believe that with this paper, the author of DeepMind may aspire to the Nobel Prize [2].
Significance: Positioning and navigation of AI is similar to that of brain cells and grid cells
In fact, this paper is the product of collaboration between the DeepMind artificial intelligence team and biologists at the University College of London (UCL).
The positioning and navigation capabilities of space are biological instincts. As early as 1971, John O'Keefe, professor of physiology at UCL, discovered a place cell in the brain's hippocampus. Then O'Keefe's student, Moser and his wife, discovered in 2005 that there is a more magical neuron, Grid Cell, in the entorhinal cortex of the brain. During the course of the movement, the living grid cells divide the space into hexagons like honeycombs, and record the trajectories on the cellular grid.
The 2014 Nobel Prize in physiology/medicine was awarded to John O'Keefe and Moser.
The artificial intelligence deep learning model is often criticized as a weakness, and it lacks the theoretical basis of physiology. The physical meaning of hidden nodes in the deep learning model cannot be explained either.
The Nature paper by DeepMind and UCL found that the hidden nodes in the deep learning model, the positional cells in the brain, and the grid cells, both have very similar activation mechanisms and numerical distributions, and are almost in a one-to-one correspondence.
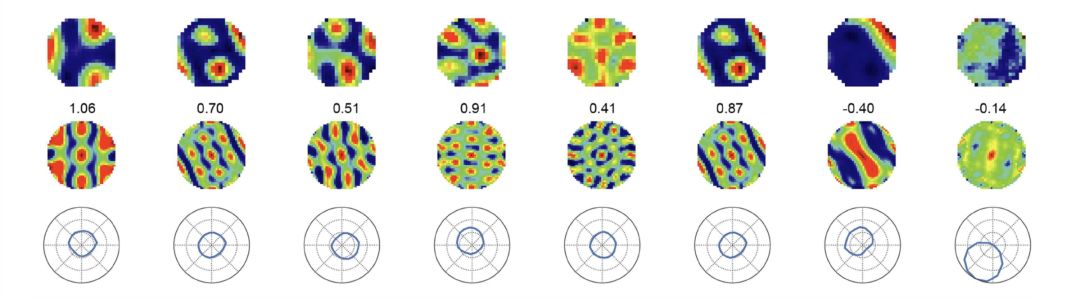
Extended Data Fig 3.d: The first line, the activation mechanism and numerical distribution of the hidden nodes of the deep learning model. In the second row, the honeycomb numerical distribution of mesh cells discovered by the Moser couple. The deep distribution of hidden nodes and grid cells is very similar. The third line, the spatial orientation and direction of motion revealed by the numerical distribution.
This paper has caused a stir in the academic world. The reason is that it proves that the deep learning model is used for spatial positioning and navigation. The physical meaning of the hidden nodes is similar to that of the brain's location cells and grid cells. It is further conjectured that the process of locating and navigating the deep learning model is likely to be very similar to the physiological mechanisms of brain positioning and navigation.
Why is DeepMind passionate about playing games?
What are the application scenarios for the deep learning model for spatial positioning and navigation? DeepMind uses this technology for video games, similar to the "Counter Strike" game in which a labyrinth shoots terrorists.
After playing the Go game under DeepMind, he played the primary video game. Now he upgraded and played advanced games. Why is DeepMind so passionate about games?
The game is a simulation system, everything is in control, what data you want, you can get what data. Therefore, each piece of data is comprehensive and there will be no data loss.
At the same time, as long as you hire more players, spend more time, how much training data, there will be more training data.
Using the game to verify the deep learning model is very convenient. This is why DeepMind is keen to play games. At the same time, DeepMind leads the world in deep learning and reinforcement learning because of its ability to quickly acquire data.

Figure 3. DeepMind applies deep learning spatial positioning and navigation technology to Counter Strike games.
The question is whether it is still effective to transfer the deep learning model applicable to games to the real world and solve practical problems.
Together with Google's brother, Google Brain is more focused on solving practical problems. The two brothers have their merits. Tensorflow developed by Google Brain has become an engineering tool, and DeepMind's paper provides new methods to lead the research front.
What are the technical innovations for deep learning papers that simulate position and grid cells?
Short answer, no unique innovation.
The long answer must first speak about Markov and reinforcement learning.
Reinforcement learning is an important branch of machine learning. It tries to solve the problem of decision optimization. The so-called decision-making optimization refers to the action (Action, A) in the face of a specific state (State, S) in order to maximize the reward (Reward, R). Many problems are related to decision-making optimization, from playing chess, to investing, to arranging courses, to driving, to walking the maze, and so on.
AlphaGo's core algorithm is reinforcement learning. Not only does AlphaGo win over all the human masters in the world today, it does not even need to learn the chess game of human players. It is completely on its own, discovering and surpassing all humanity accumulated over more than a thousand years in just a few days. Go strategy and tactics.
The simplest mathematical model for reinforcement learning is the Markov Decision Process (MDP). The reason why MDP is a simple model is because it imposes many restrictions on the problem.
1. The face of the state s_{t}, the number t = 1 ... T, T is limited.
2. The action plan a_{t} taken, the number t = 1... T, T is also limited.
3. Corresponding to the specific state s_{t}, the current return r_{t} is clear.
4. At some time t, the action plan a_{t} is taken and the state transitions from the current s_{t} to the next state s_{t+1}. The next state s_{t+1} has many possibilities. The probability of transitioning from the current state s_{t} to one of the next states is called transition probability. However, the transition probability depends only on the current state s_{t}, but not on the previous state, s_{t-1}, s_{t-2} ....
The commonly used algorithm for solving Markov decision process problems is Dynamic Programming.
Restrictions on Markov's decision-making process and constant research on corresponding algorithms are the goals of reinforcement learning.
For example, relax the restrictions on the state s_{t},
1. If the number of states s_{t} is t = 1... T, T is finite, but the number is huge, or there are infinite numbers. How to improve the algorithm?
2. If the state s_{t} cannot be completely determined, it can only be partially observed, and the remaining part is occluded or missing. How to improve the algorithm?
3. If the transition probability depends not only on the current state but also on the previous trajectory, how can the algorithm be improved?
4. If you encounter a new state s_{t} that you have not previously encountered, is it possible to find a similar state in the state that you have encountered in the past and estimate the transition probability and estimate the gain?
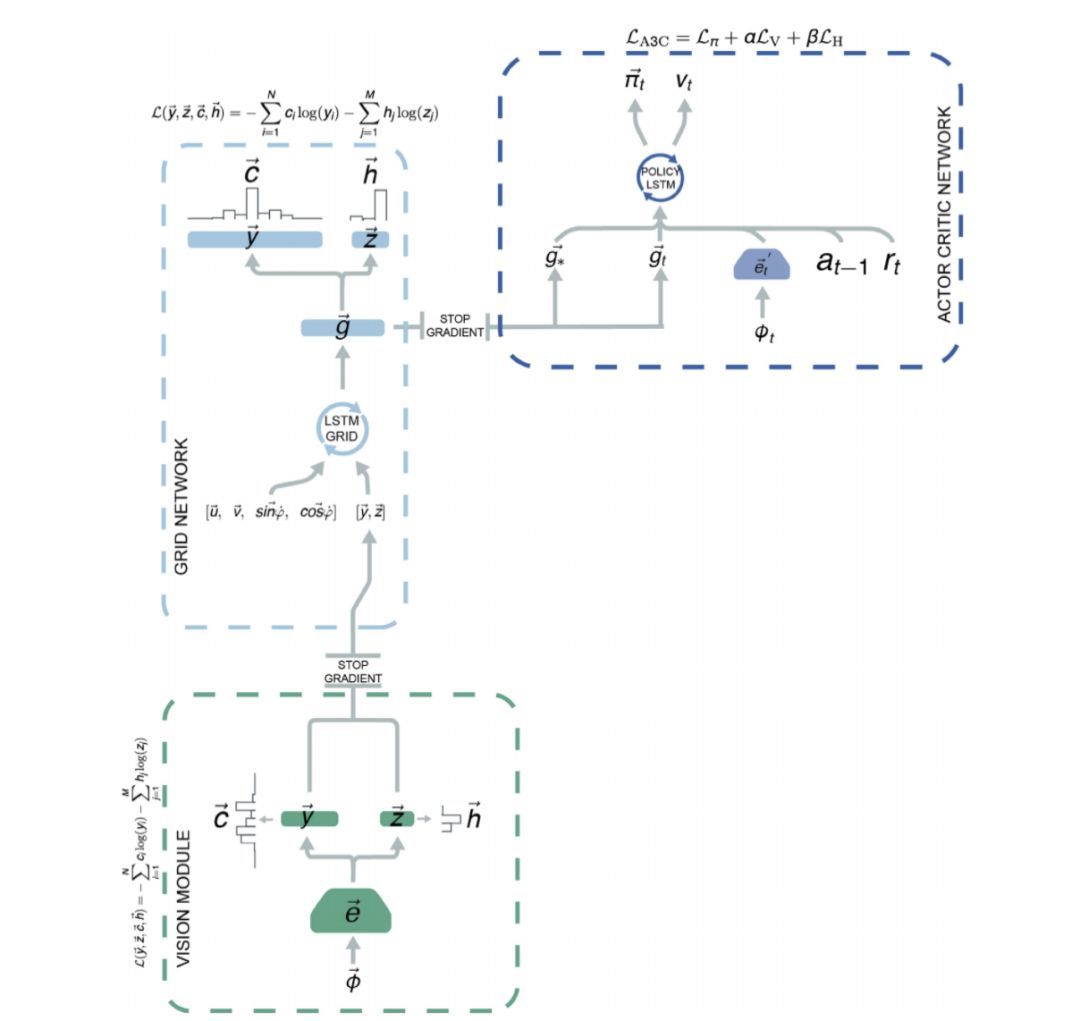
Extended Data Fig 5. Use Grid LSTM to summarize the past trajectories and add the neural network g to determine the current spatial orientation and direction of motion. Then based on the judgment of the current spatial positioning and navigation, another LSTM is used to estimate the probability of state transitions to determine the navigation strategy.
This paper uses a deep learning model to simulate position and grid cells. Specifically,
1. Use CNN to process images and find landmarks in the surrounding environment to identify the current spatial location.
2. Combine the results of image processing with previous motion trajectories and use Grid LSTM to estimate the current state.
3. The current state estimated by Grid LSTM is reworked by a neural network g to obtain hidden nodes similar to the location cells and grid cells.
4. Determine the navigation decision by using the current position and direction of movement, and the position of the target, as input to the second LSTM model.
All of the above modules are integrations of off-the-shelf technologies and there are no significant innovations.
Thunderbolt Cable
Shenzhen GuanChen Electronics Co., Ltd. , https://www.gcneotech.com