MHA Jedi is a well-established implementation of a MySQL High Availability solution. It handles data switching efficiently, and when combined with MGR (MySQL Group Replication), it performs even better at the data level. However, there's still room for improvement in terms of access IP management. MHA offers a variety of optional configurations to support different environments.
Common combinations include:
- MHA + VIP
- MHA + Keepalived
- MHA + Zookeeper
Among these, MHA + VIP is a mature and widely used solution. In general, the architecture often follows a one-master-two-slave model. Applications connect via a VIP address, which can be moved between nodes based on the database's state, ensuring smooth failover without service interruption.
The MHA Manager is a central scheduler that manages multiple environments. However, it has a single point of failure, so it's common to set up two MHA Manager nodes for redundancy. For example, in a 100-environment setup, each manager could handle 50 environments. If one fails, the
other can take over seamlessly.
From the application side, all traffic goes through the VIP. If you add middleware solutions on top of this, the data access strategy becomes more complex.
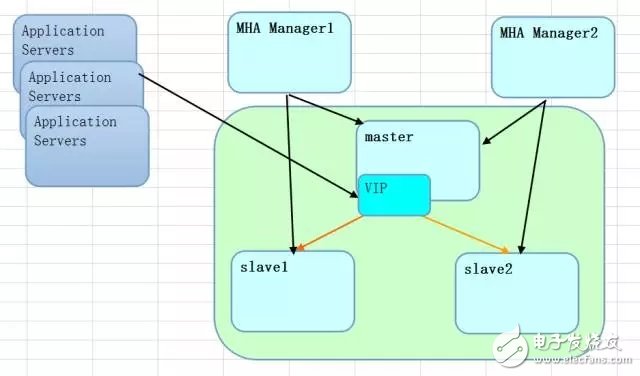
This basic setup requires careful consideration from multiple angles. There are many potential issues, but MHA addresses most of them. Key scenarios to consider include:
- Master database downtime
- Slave database issues
- Restarting the master or slave
- Application delay on the slave
- Network delays between master and slave
- Server failures on either master or slave
- Priority settings during multi-slave failover
- Network jitter affecting switch decisions
- Manual master-slave switching
- IP changes for master or slave
- Adding or removing slave nodes
- Preventing network jitter
- Impact of semi-synchronous replication plugins
- Custom MHA scripts
These scenarios must be carefully planned. As shown in the diagram, there may be red warnings indicating potential problems. The goal is to minimize business impact and ensure continuous access.
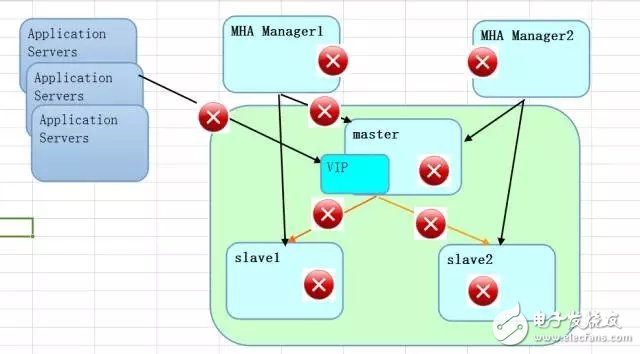
Now, imagine a more complex situation: if the MHA Manager node experiences network jitter and becomes temporarily unreachable, should it trigger a failover? If the issue lasts only a few minutes, maybe not. But if it persists longer, such as 2–3 minutes, then a failover might be necessary. This decision depends on whether the application is affected or not.
In practice, there are differences between MHA versions like 0.56 and 0.57. Through extensive testing across multiple environments, it becomes clear that MHA covers a wide range of scenarios. Understanding these nuances helps in mastering MHA and identifying hidden issues. Customizing MHA to fit specific business needs can make it more responsive and effective in real-world situations.
Video Brochure
Video Brochure, Video Brochure Card, LCD Video Brochure
AST Industry Co.,LTD , https://www.astsoundchip.com
